Coarse Programmers guide to faking new Wagtail rich text entities
Dec. 3, 2015
I have begun creating online courses using the Django based CMS Wagtail. Like Django and the Python language in which they are written, I find it easy to understand. This is ideal for a coarse programmer who doesn't have time or interest to be staying on top of constantly changing targets.
Unfortunately, the backend admin site of Wagtail is becoming more and more JS-heavyas I discovered when I tried to extend the rich text editor for one of my courses. My need was simple enough. I wanted a version of the hyperlink button, but with the ability to add a few extra attributes, such as the title of the page and publisher.
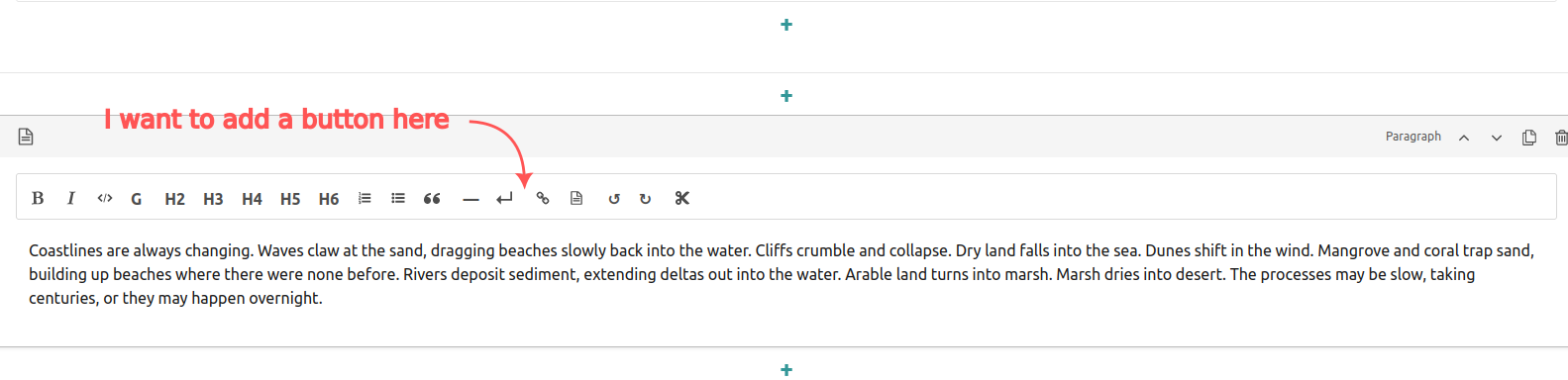
The attributes could be used to create a sidebar with bibliographical references. You can see it in action on the course I'm co-producing on Coastal Resilience for Journalists. (Click the link icons in the text to see the sidebar).
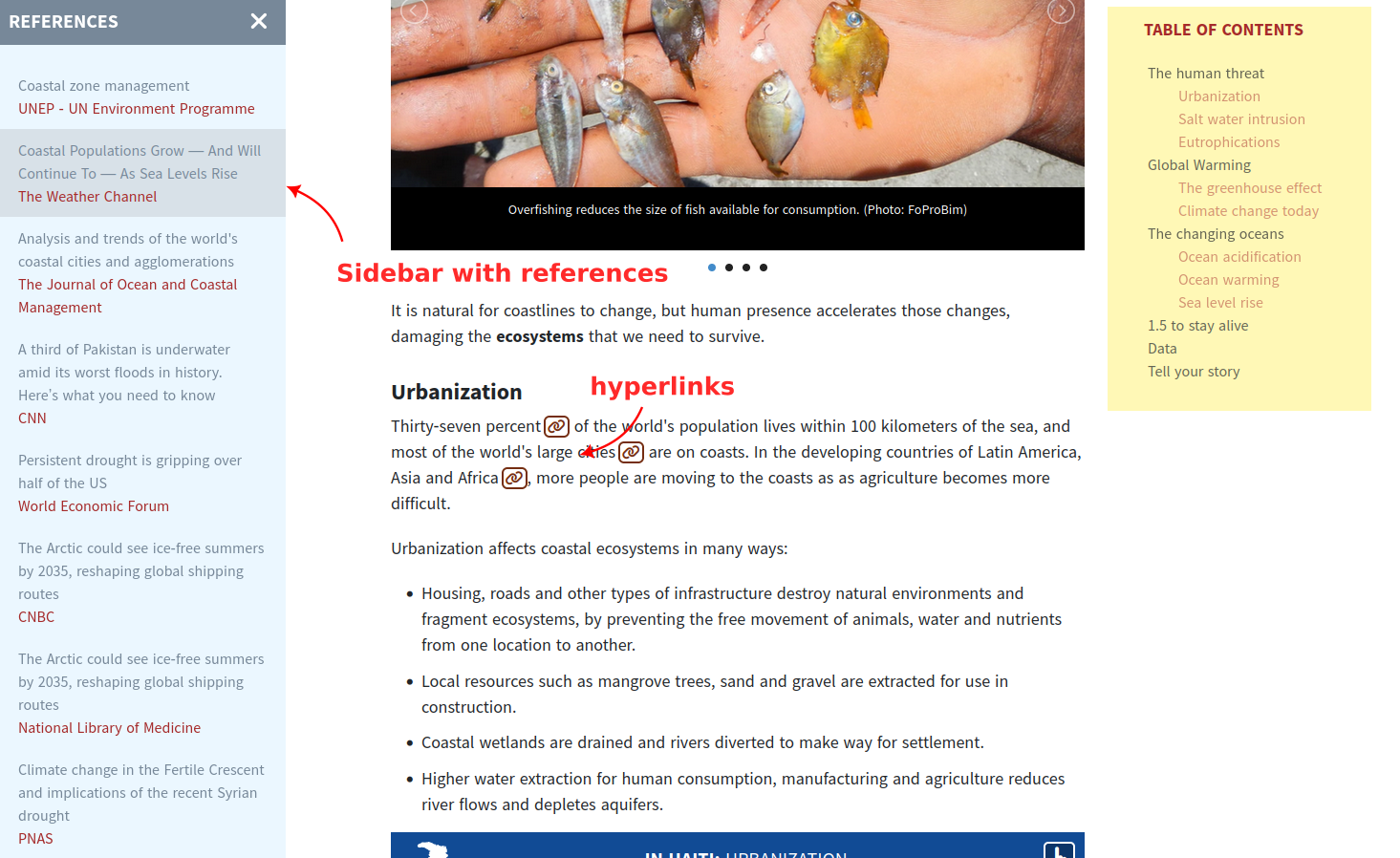
This seems like a simple need. It took me an hour to do something like this with CKEditor. But the Wagtail docs are pretty clear that this is not to be taken lightly:
Well, I considered carefully and was pretty sure I needed it. But there was no way I was going to venture into React-land after that warning. I just don't have the time. Here's how I faked it.
I call my page model Module (because each page is a module in an online course). The main content of each module is stored in a Wagtail StreamField called content.
# home/models.py from wagtail.models import Page from wagtail.fields import StreamField from wagtail import blocks from wagtail.images.blocks import ImageChooserBlock class Module(Page): content = StreamField([ ("heading", blocks.CharBlock(template= "blocks/heading.html")), ("paragraph", ModuleRichTextBlock(editor="full")), ("quiz", blocks.CharBlock(template="blocks/quiz.html")), ("image", ImageChooserBlock()), ], use_json_field=True)
The content field is composed of various Wagtail StreamBlocks. The one we're concerned with is paragraph. Paragraph is a subclass of a Wagtail RichTextBlock. That is where I wanted to add the custom editor button. We'll return to it shortly.
# home/models.py from wagtail import blocks class ModuleRichTextBlock(blocks.RichTextBlock): def render(self, value, context=None): # to be revealed .....
I also have a snippet model to contain the url and extra attributes for each link.
# home/models.py @register_snippet class Link(models.Model): # Fields created automatically by sync_links management command module = models.ForeignKey("Module", on_delete=models.CASCADE, blank=True, null=True) lid = models.IntegerField(blank=True, null=True) #lid = link id url = models.URLField(unique=True) # Extra info added later by hand page_title = models.CharField(max_length=150, blank=True, null=True) source = models.CharField(max_length=150, blank=True, null=True) description = models.CharField(max_length=300, blank=True, null=True) def __str__(self): return self.source or self.url class Meta: ordering = ["lid", "id"]
Each link has a ForeignKey to the module it appears in. The lid (link id) field is used for sorting the links in the order they appear in the page.
Then I created a django management command called sync_links.py. This goes through the paragraph field of each page searching for links. It creates a new Link object for any new URLs it finds, with a ForeignKey to the Module (ie. page) it was found on.
# management/commands/sync_links.py from json import dumps import re import requests from bs4 import BeautifulSoup as bs from django.core.management.base import BaseCommand, CommandError from wagtail.core.fields import StreamField from home.models import Module, Link class Command(BaseCommand): help = 'Creates Link objects from new entries in module content.' def add_arguments(self, parser): parser.add_argument('mids', nargs='*', type=int) def handle(self, *args, **options): mids = options["mids"] # optinally indicate which module you want to sync, # otherwise go through them all if not mids: modules = Module.objects.all() else: modules = Module.objects.filter(id__in=mids) for module in modules: # module.content is a StreamField field that contains all the text for the module # get_prep_value converts it to a list of dicts, containing the content as html # plus other bits and bobs content = module.content.get_prep_value() urls = [] # Loop through each block searching for links for block in content: if block["type"] == "paragraph": value = block["value"] # the content as html soup = bs(value) link_tags = soup.find_all("a") for tag in link_tags: hrefs = [tag["href"] for tag in link_tags if tag.get("href", None)] urls.extend(hrefs) for i, url in enumerate(urls): link, flag = Link.objects.get_or_create(url=url) # If the link already exists, the url does not # need to be updated. Neither do the lid or module # if the link has not changed its position in the # text or the module it appears in. But its simpler just # to set them anyway. link.url = url link.lid = i link.module = module link.save()
I'm using BeautifulSoup to find the link tags. It's probably overkill. I could have just used a regex, but my head hurts every time I consult the python regex guide.
I can run sync_links.py any time I add links to a module or change their position in a page (for example if I change the order of paragraphs containing links). Any prexisting links will be updated and duplicates will not be created. There are many loopholes in this implementation. For example, it won't delete Link objects from the database if the corresponding hyperlinks are deleted from the text. But for my limited usage, this suffices.
After I run this command, I get a list of link snippets in the admin.
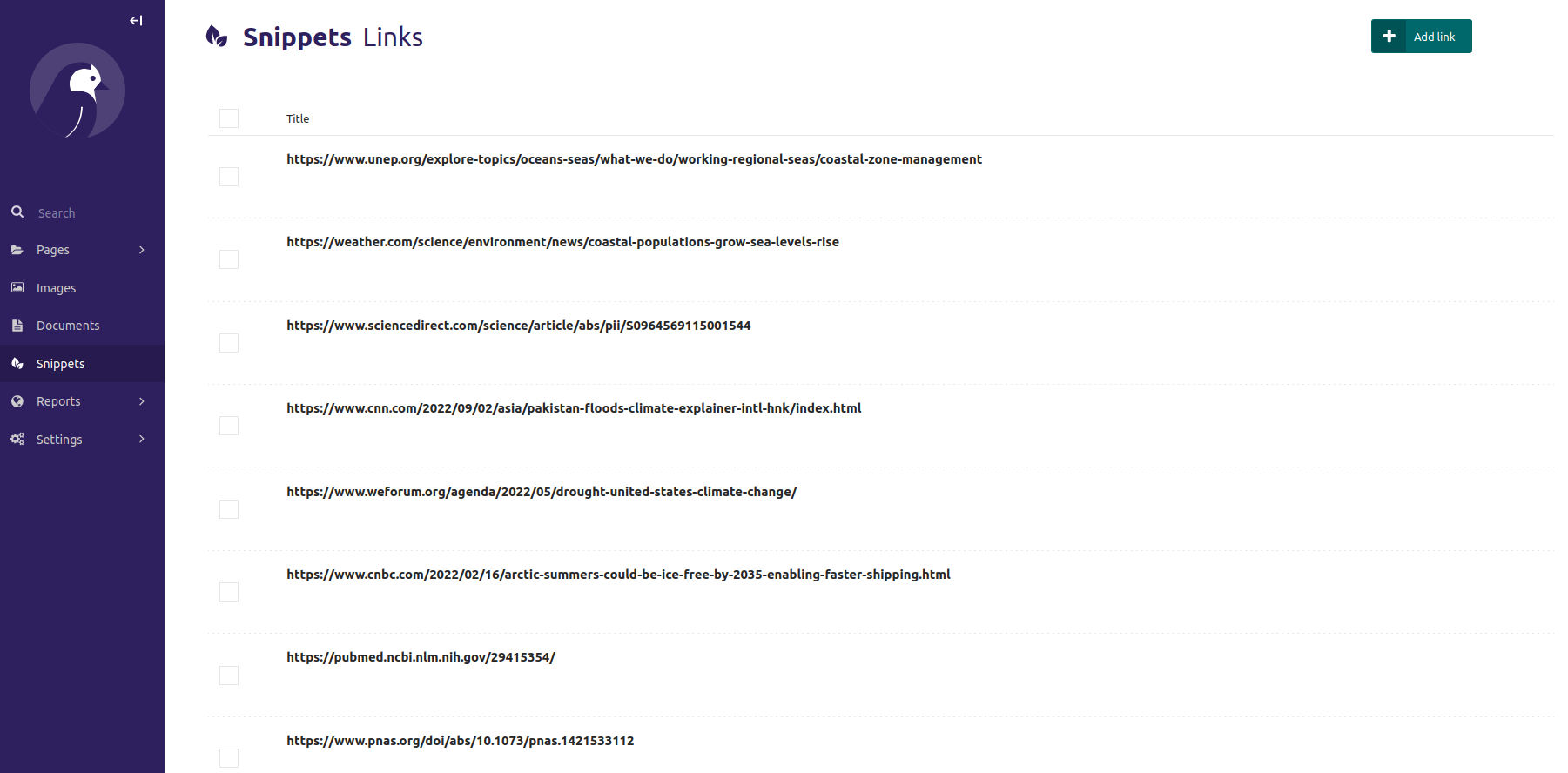
I can then add page titles and publisher at my leisure. I realized that this is actually a bit more comfortable than trying to add the info when I'm in the throes of writing, so maybe I actually didn't need to create that Rich Text Editor button. I should have considered harder.
To create the sidebar with the list of references for the page, I override the render method for the ModuleRichTextBlock.
# home/models.py from bs4 import BeautifulSoup as bs from wagtail import blocks class ModuleRichTextBlock(blocks.RichTextBlock): def render(self, value, context=None): # Loop through the <a> tags, find them in Link.objects, and assign them # an id so they can be matched with the sidebar links source = value.source soup = bs(source) link_tags = soup.find_all("a") if link_tags: for tag in link_tags: url = tag.get("href", None) if url: link, flag = Link.objects.get_or_create(url=url, module=context["page"]) # tag.unwrap() marker = soup.new_tag("i") marker["class"] ="link fa-solid fa-link" marker["id"] = "link-" + str(link.id) tag.append(marker) tag.unwrap() soup.smooth() value.source = str(soup) return super().render(value, context)
This intercepts the rendering, removing the link from the enclosed text, adding a font-awesome icon after the text and an id to the icon that corresponds to the link object in the database. Once again I use BeautifulSoup, where probably a regex would do.
I then override the get_context method on the Module page itself to include the Link objects for that Module.
# home/models.py from wagtail.models import Page class Module(Page): .... def get_context(self, request, *args, **kwargs): context = super().get_context(request, *args, **kwargs) context['links'] = Link.objects.filter(module=self) return context
The links are rendered in the template in a sidebar that slides in and out when the link icon is clicked. A very simple bit of jquery checks the id on the link and scrolls to the corresponding reference in the list.
I doubt this is the best way to achieve what I need, but it was the fastest way I could think of without getting distracted from my real task, which is creating the actual content. I do know that instead of using a custom render method to modify the links in the html every time the page is loaded, I could save those changes to the database in the same sync_links.py command that creates the Link objects. This page has a good example of how to do this.
However, doing this entails messing around with Wagtail's revisions models and the distinction between drafts and published pages. I don't understand these models, so for now I'm sticking with what I've got.
- A demonstration of how to create a simple Wagtail Rich Text entity the proper way by a Wagtail contributor.
- Advice on creating a complex inline entity... basically, don't. Previous posts have good tutorials on creating custom blocks.


