
Coarse Programmer's Guide to Scraping: Know your URLs
June 8, 2018
This is the first in what I hope will be a series on "Coarse Programming". The Art of Coarse Acting is a hilarious guide to acting without really being an actor. These guides (if I really do write more than one UPDATE: I have.) are about programming without being a programmer.
If you're here you probably already know what scraping is. I am developing an application called Newsicles that scrapes local news websites and other news sources and uses natural language processing (NLP) to identify entities (people, places, organization etc.) and the connections between them. The first step is to scrape newspapers for articles on selected topics. I use the python package Scrapy to scrape a list of websites, extracted all the urls on the sites, then check headlines against a list of topic keywords, saving any articles that contain the keywords. I use the spacy NLP package to stem the keywords, and search for grammatical variants.
When I first started scraping newspapers, I thought all you had to do was give Scrapy a starting URL and wait for it to reel in everything it links to. I knew you'd get a little by-catch in the process but figured that as long as what you want is reachable from your starting point you'll eventually get it. It is in the nature of coarse programming to make such assumptions. It saves time on reading documentation. You can just scan it quickly for the bit of sample code that does exactly what you want. I did this, then threw Scrapy an URL and sat back.
After hours of watching the Scrapy logs roll past, I realized that I was doing approximately this:

Say an article of interest is ten links removed from the starting URL. If we assume very conservatively that each page links to just three other pages, and I'm checking them all, I will have scraped 29524 pages just to get that single article. I stared at the logs some more.
From the logs I realized that part of the problem was that I was allowing my spider to follow links off-site. Most of the newspapers I am targeting are larded with ads, facebook links and whatsapp share buttons, and my spider was following them all! Looking even more closely at the logs, I also see that it was also wasting time by following category pages that clearly weren't going to having anything interesting for: the sports section, social pages, commentaries. I know now that the designers of Scrapy already anticipated this problem, and allow you to designate links to ignore and apply constraints like staying on-site. But since I didn't read the documentation, I just blithely went ahead and built my own filter.
def remove_ignore_links(links, ignore_links): return list(set(links)-set(ignore_links))
While blacklisting links will slow the growth of your trawl, it doesn't change the fact that the crawl is by nature geometric and wants to bloat in every direction possible. I tried limiting my search by adjusting Scrapy's depth parameter. For each page Scrapy parses, it keeps track of how many links it followed to get there. You can tell it to ignore pages whose chain of links exceeds a certain number. I thought I could approximate a date range by starting my crawl from an article with a given date, and use the depth parameter to limit how far back in the past it went. Here's a histogram of the number of saved articles by publishing date.
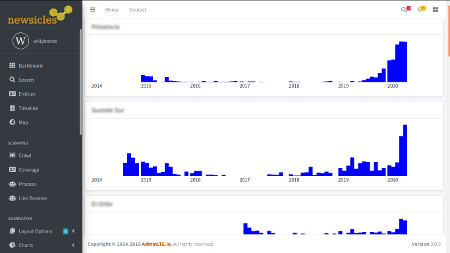
The humps at either of show that most of my hits were clustering around the start date and working backwards, but the spider also seemed to be scraping from far back as possible, leaving an unscraped desert in the middle. Changing the depth would sometimes limit how far back in time the spider went, but not always, and I was still getting hits from up to 10 years ago. The reason is painfully obvious now, but it took me hours of staring at the logs to understand. Many newspaper sites have archival links that allow you to skip to the first, second, third page of entries, or even right to the last page. So a link to "/archivo/noticias/page/649" will still be only one link deep from the start page, even if it leads all the way to the first page ever created on the site. Duh.
Clearly, my gobble-everything-blindly strategy was not going to work. I needed more finesse in my scraping. I would need to actually visit these sites, find out how their stories are categorized and how their archives are structured. I really did not want to do this. The sites are very messy, they load MBs worth of javascript, trackers and ads and each uses a different template. I didn't want to spend hours browsing each page trying to understand the idiosyncracies of their structure.
So I built this link browser into the Newsicles suite.
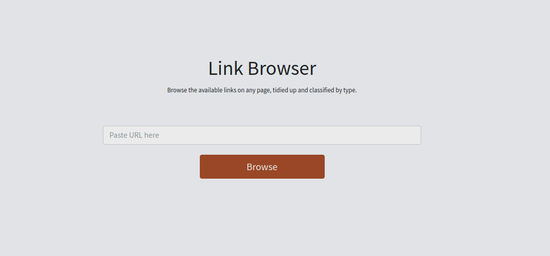
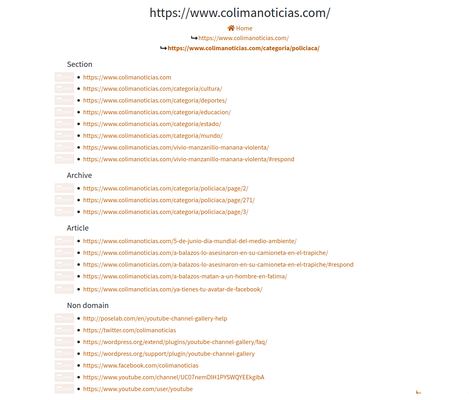
This is a simple Django app that takes any URL, parses the page, extracts the links with Beautiful Soup, eliminates duplicates, rewrites relative links in their absolute form, sorts them and displays them in categories. I'm sure many others have created the same service, and in more elegant code, but in the true spirit of the Coarse Programmer I didn't even know this was a problem that needed a solution until I created mine.
# Takes a list of urls extracted from a page (links), and the url of the page from which # they are extracted (base_page). Returns dictionary of categorized urls. def link_filter(links, base_page): domain = urlparse(base_page).scheme + "://" + urlparse(base_page).netloc # create an alternate domain to filter against, using either https or http, whichever # the original domain isn't if domain.startswith("http:"): domain_alt = domain.replace("http:", "https:") else: domain_alt = domain.replace("https:", "http:") links = set(links) urls = { "main": [], "non_domain": [], "article": [], "archive": [], } for _link in links: if not _link.startswith(domain) and not _link.startswith(domain_alt): if _link.startswith("http"): urls["non_domain"].append(_link) else: # create absolute url from relative _link = domain.rstrip("/") + "/" + _link.lstrip("/") if _link.startswith(domain) or _link.startswith(domain_alt): if len(re.findall("(\w-\w)", _link))>3: urls["article"].append(_link) elif re.findall("(/\d+/*$)", _link): urls["archive"].append(_link) else: urls["main"].append(_link) for k,v in urls.items(): v.sort() return urls
The app sorts the links into four categories using simple regular expressions:
- Articles: These are stories, containing slugs consisting-of-alternating-words-and-hyphens
- https://www.dominio.com/maria-isabel-martinez-flores-se-integrara-como-diputada-local-la-proxima-semana/
- Archival: These are the links that take you to the second, third, fourth and so on of any category. I identify them by having a / followed by digits at the end
- https://www.dominio.com/archivo/noticias/page/10/
- Topic: Any other on-site link. The majority of them lead to categories like "sport", "local", "national" etc.
- https://www.dominio.com/policiaca
- Off site: Links that don't begin with the same domain as the starting page
- https://web.whatsapp.com/send?text=Hallan%20muerto%20a%20comerciante%20reportado%20 como%20secuestrado%20en%20Cuichapa%2C%20Veracruz%20http%3A%2F%2F
If I'm only interested in the the structure of links and the layout of the site, rather than the actual content, browsing the site with Link Browser is a much more relaxing experience than wading through the cruft of multiple wordpress blogs. I can easily identify what URLs I need, which ones I can add to an ignore list. Best, I can identify archival pages.
The key is identifying the archival pages. For example http://newspaper.com/state/12. Changing the number on the end allows me to specify a list of urls spanning given page numbers.
class Spider(Spider): def start_requests(self): base_url = http://newspaper.com/estatal/ urls = [base_url + str(i) for i in range(15,25)]
Now, instead of spanning out across the site and beyond, I traverse a defined series of archival pages and scrape what I find there. I only need to set the depth to one because I'm only interested in the news stories on each of these pages. My crawling now looks more like this:
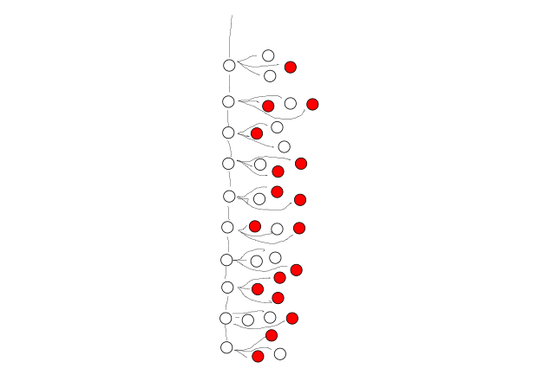
In retrospect, this is all painfully obvious and probably Scraping 101 for anybody who dedicates professional career time to it. But since I only dabble in scraping, and am more fixated on the data I was trying to get than the process by which I was going to get it, I didn't know any of it. I hope this article is interesing for other coarse programmers interested in scraping. You're welcome to use Link Browser. (Just keep in mind it does all the parsing on the server, so although I've got better things to do than spy on my visitors, your searches are not private.)


